- Inductive bias (귀납적 편향)
: 기계학습에서의 inductive bias는 학습 모델이 지금까지 만나보지 못했던 상황에서 정확한 예측을 하기 위해 사용하는
추가적인 가정을 의미합니다.
학습이 성공적으로 끝난 후에, 학습 모델은 훈련동안에는 보이지 않았던 예들 까지도 정확한 출력에 가까워지도록 추측해야합니다.
이럴 때 추가적인 가정이 없이는 불가능한데, 이 Target function의 성질에 대해 필요한 가정과 같은 것이 Inductive bias라고 볼 수 있습니다.
: Inductive bias 해결을 위한 구성 요소
• Priors: things assumed beforehand (사전 지식 기반)
Priors는 학습이 쉽지만 사전지식 오류시 문제가 발생하거나 유연하지 않을 수 있습니다.
• Learning: things extracted from data (데이터로 부터 추출)
Learning은 유연하지만 학습하기가 어려운 단점이 있습니다.
- Neural network와 이미지 처리
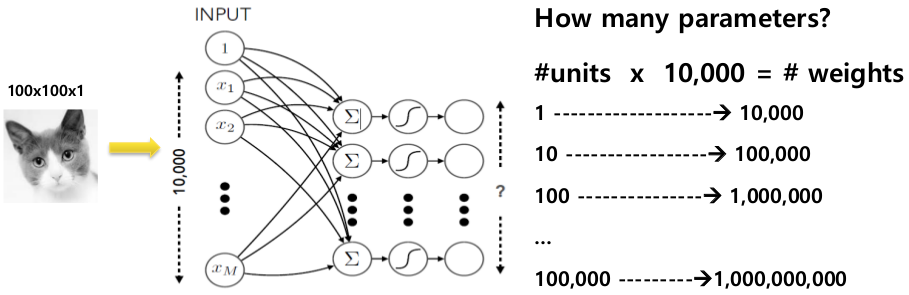
: 전통적인 Neural network는 학습해야 할 parameter가 너무 많아 차원이 높은 데이터에 적합하지 않습니다.
parameter가 증가할 수록 처리해야할 데이터의 양은 기하급수적으로 증가합니다.
이 문제를 해결하기 위한 CNN은 이미지 분야에서 많이 사용됩니다.
- Convolutional networks
: CNN(Convolutional Neural Network)은 이미지를 분석하기 위해 패턴을 찾는데 유용한 알고리즘으로 데이터에서 이미지를 직접
학습하고 패턴을 사용해 이미지를 분류합니다.
신경망의 행렬 곱셈을 컨볼 루션으로 대체 (컨볼 루션 연산으로 대체, 반복)하는 과정을 가집니다.
CNN의 핵심적인 개념은 이미지의 공간정보를 유지하며 학습을 진행합니다.
CNN은 필터링 기법을 인공 신경망에 적용함으로써 이미지를 더욱 효과적으로 처리하게 해줍니다.
- 매우 큰 이미지 / 비디오 시퀀스를 처리하기 위해 신경망 확장
• Sparse connections (인접한 노드끼리 모두 연결하지 않는다.)
• Parameter sharing (파라미터를 공유, 반복된다고 가정)
- 입력의 공간 번역에서 자동으로 일반화
- 그리드에 배치된 모든 입력에 적용 가능 (1-D, 2-D, 3-D, ...)
: 처리과정
Fully Connected layers: 고전적인 방법입니다.
Convolutional layes: pooling layer는 down sampling 단계, 마지막 단은 고전적인 방법과 거의 비슷합니다.

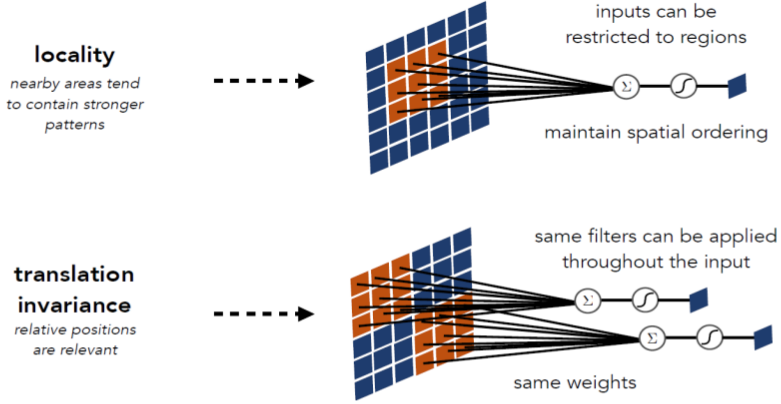
- Spatial structure in images (이미지의 공간 구조)
: Locality
• Nearby areas tend to contain stronger patterns (가까운 지역의 pixel 들이 더욱 관계가 있다.)
Translation invariance
• Relative (rather than absolute) positions are relevant (사물의 종류는 위치에 상관없다.)
Exploit spatial structure in images (이미지의 공간 구조 활용)
locality의 node는 전체가 아닌 size를 정한 값의 linear combination 입니다.
translation invariance는 위치에 상관없이 특정 물체를 탐지하기 위해 같은 필터를 이동해가며 계산합니다.
- Feature maps
: Convolution Layer의 입력 데이터를 필터가 순회하며 합성곱을 통해서 만든 출력을 Feature Map 또는
Activation Map이라고 합니다. Feature Map은 합성곱 계산으로 만들어진 행렬입니다.
input image로 부터 filter size를 정한 후 feature maps에 hidden node를 만듭니다.
filter의 갯수만큼 feature output map이 생성됩니다.

- Architecture overview
: 더이상 고전적으로 fully connect 하지 않기 때문에 convolution은 표현하는 방법이 다릅니다.

- Convolution
: 컨볼루션(convolution)은 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 다음, 구간에 대해 적분하여 새로운 함수를 구하는
수학 연산자입니다.
: Convolution 방법
이미지의 특정 지역과 Kernel(filter) 간의 내적 계산입니다.
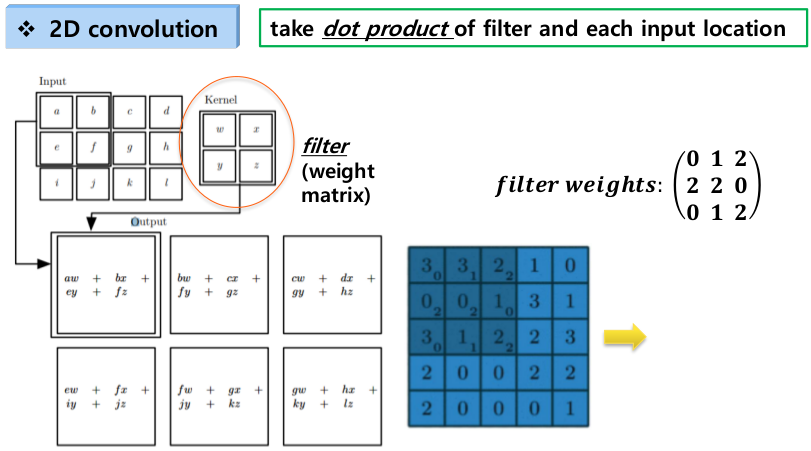
Example 1.

: Convolution with bias
bias를 넣으면 위치를 이동시킬 수 있기때문에 modeling을 유연하게 할 수 있습니다.
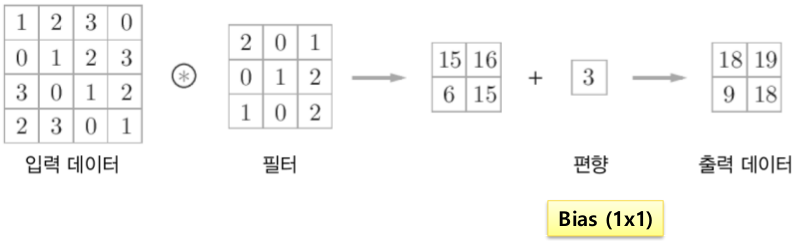
Example 2.
: 고역 통과 필터처럼 작동 : 가장자리 근처의 픽셀이 살아남습니다.
최신 라이브러리 및 GPU에서 매우 효율적으로 수행 할 수 있습니다.

- Padding
: 패딩이란 콘볼루션 연산 전에 입력 데이터 주변을 특정값으로 채우는 것입니다
filter size에 따라 가상의 pixel을 만들고, 보통 0으로 채웁니다.
1줄, 2줄, 3줄 등 상황에 따라 갯수를 달리 할 수 있습니다.

: Zero-Padding
바깥 쪽의 열과 행을 0으로 채워 Convolution하여 결과 값의 행렬의 크기를 유지할 수 있습니다.

- Stride
: 스트라이드는 입력데이터에 필터를 적용할 때 이동할 간격을 조절하는 것, 즉 필터가 이동할 간격을 말합니다.
스트라이드 또한 출력 데이터의 크기를 조절하기 위해 사용합니다.
Convolution 진행시 Stride의 값만큼 Pixel을 이동합니다.


- Multiple channels
: input channel이 RGB로 3가지일 경우, filter size도 depth에 맞추어 정해주어야 합니다.

: 3D convolution

- Pooling
: pooling 이란, downsampling을 한다는 뜻으로 Max pooling의 경우 가장 큰 값만 다음 layer로 넘깁니다.
이를 진행함으로써 input variation이나 noise에 강해질 수 있습니다.
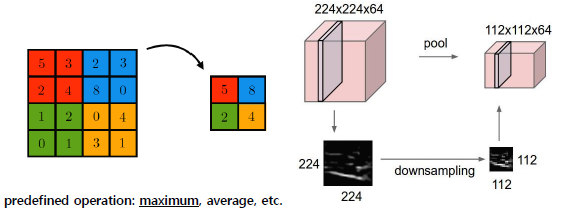
: Max pooling
- The most common downsampling operation

- Layers in CNN
: convolutional layer에서는 각각의 locality patch들이 filter와 convolution이 되어 output 값 도출,
사용된 filiter에 갯수에 따라 depth가 정의됩니다.
pooling layer는 downsampling 등 변환 과정입니다.
fully connected 과정에서 모든 feature map 값을 최대한 mix하여 최종 값을 도출할 수 있습니다.

- Convolutional Neural network
: 컨볼 루션 풀링 레이어로 구성된 심층 신경망

- Classification layer
: 분류를 수행하기 위해 많은 CNN이 사용됨
이러한 CNN의 최종 레이어는 클래스 확률을 나타내는 데 사용됩니다.

- 소프트 맥스 레이어는 확률을 지정하므로 비용을 다르게 계산해야합니다.
- 교차 엔트로피 : 두 분포 간의 차이에 대한 정보 이론적 측정 (두 분포사이의 차이를 계산하기 위해 사용)
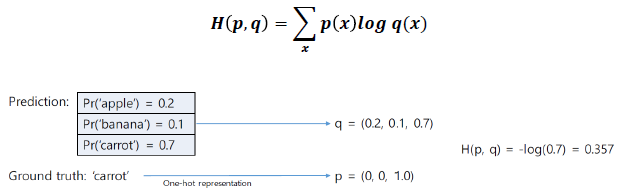
- 최종적인 softmax 값이 나오면 정답과 얼마나 가까운지를 측정하여 loss 값으로 사용합니다.
- loss는 결국 error 값과 비슷하므로 작으면 작을수록 자신의 모델이 정답을 잘 맞춘다는 의미입니다.
- loss function을 기반으로 gradient를 계산하여 backpropagation으로 모델 parameter 들을 구합니다.
- 대부분의 복잡한 계산을 수행하는 Convolutional Network의 핵심 빌딩 블록
- 로컬 연결성
• 각 뉴런을 입력 볼륨의 로컬 영역에만 연결
•이 연결의 공간 범위는 수용 필드라고하는 하이퍼 파라미터입니다 (동일하게 필터 크기).
- 공간 배치
• 3 개의 하이퍼 파라미터가 출력 볼륨의 크기를 제어합니다 : 깊이, 보폭 및 제로 패딩.
- Training CNNs
- Back propagation
• SGD, Adam, AdaDelta , AdaGrad , etc
- (Trainable) parameters
• Kernel patch for each layer
• bias vectors for each kernel
- (non trainable) hyperparameters
• Network depth
• Number of kernels per layer, kernel size, stride, zero padding
• Which activation functions
아주대학교 정보통신대학원 손경아 교수님의 기계학습 및 데이터 마이닝 강의를 바탕으로 작성하였습니다.
학습 목적으로 포스팅 합니다.
'Machine Learning' 카테고리의 다른 글
| Recurrent Neural Network (0) | 2020.10.17 |
|---|---|
| Artificial Neural network (0) | 2020.10.01 |
| Neural network: perceptron (0) | 2020.10.01 |
| Logistic regression (0) | 2020.09.29 |
| Model selection (1) | 2020.09.29 |