- Supervised learning
Supervised learning (지도 학습)은 훈련 데이터로부터 하나의 함수를 유추해내기 위한 기계 학습의 한 방법입니다.
훈련 데이터는 입력 객체에 대한 속성을 벡터 형태로 포함하고 있으며 각각의 벡터에 대해 원하는 결과가 무엇인지 표시되어 있습니다.
Supervised learning에서 나오는 분류(Classification)와 회귀(Regression)는 Supervised Learning의 목적이라 할 수 있습니다.
Supervised learning은 주어진 x 데이터로 부터 y를 예측합니다. (Given X∈x, predict Y∈y.)
Classification은 보통 몇 개의 고정 변수(discrete variable) 중 하나를 예측하는 것으로 Y가 집단 (카테고리, 분류...)입니다.
어떤 사진을 보고 고양이인지 개인지 구분하는 것은 예측하는 Y가 두 가지 중 하나이기 때문에 고정 변수가 두 개인것입니다.
Regression은 연속변수(continuous variable)를 예측하는 것으로 Y가 숫자 (판매량, 주가, 수치..)입니다.
연속값이란 숫자 사이 사이에 무한 개의 가능한 값이 있는 것을 의미합니다.
- Classification(분류): two stage process
1. Learning (training): 훈련 데이터를 통해 분류기가 데이터를 학습하도록 합니다.

2. Prediction: 학습 된 분류기를 사용하여 새 데이터에 대한 레이블을 예측합니다.

- Over-fitting for training data
분류기는 Training 데이터에서만 성능이 좋은 것이 아니라, Test 데이터에서도 성능이 좋아야 합니다.
하지만 Training 과정에서 해당 데이터에 대해서만 과하게 학습할 경우, Test 데이터에 대해서는 좋은 성능을 낼 수 없습니다.
이러한 경우 Training 데이터에 대해서는 오차가 감소하지만, Test 데이터에 대해서는 오차가 증가하고 Over-fitting 되었다고 합니다.

- Over-fitting을 피하는 방법
1. 데이터 크기에 따라 80:20, 70:30, 90:10 비율로 Train/Test 데이터 분리
· We need enough training data as well as enough test data...
· Or use cross-validation (교차 검증)
2. Training/Validation 데이터와 Test 데이터 분할
· For model selection, hyper-parameter(ex. node, layer...) tuning
- KNN algorithm
k-Nearest Neighbors (k-NN, k-근접이웃) 알고리즘 이란 특정공간내에서 입력과 제일 근접한 k개의 요소를 찾아,
더 많이 일치하는 것으로 분류하는 알고리즘입니다. k 값(hyper-parameter)에 따라서 결과가 달라질 수 있습니다.
Training 단계에서 학습되는 parameter는 없고, 모든 일은 Test 단계에서 일어납니다.
1. k에 해당하는 숫자와 거리 메트릭 선택
2. 분류하고자 하는 샘플에 대한 k개의 근접이웃 찾기
3. 다수결 투표 방식으로 분류 레이블 할당
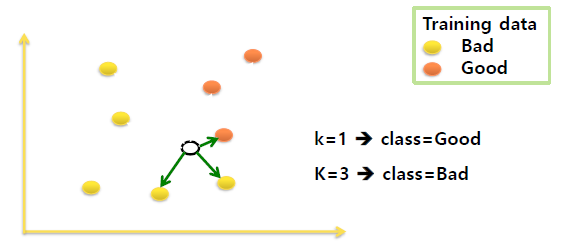
Neighbor size k 를 설정할 때, k의 적절한 값 선택은 데이터 세트에 따라 달라집니다.
k가 작을 경우 분산의 문제가, k가 클 경우 편향의 문제가 발생할 수 있습니다.
: Smaller k -> higher variance (less stable)
: Larger k -> higher bias (less precise)
- Variance of Learing Methods (분산)
: 예측값들이 자기들끼리 대체로 멀리 흩어져있으면 결과의 분산(variance)이 높다고 한다.
: 분산은 다른 훈련 데이터 세트가있는 경우 추정치가 얼마나 변경되는지를 나타냅니다.
: 일반적으로 방법이 더 유연할수록 더 많은 분산이 있습니다.
- Bias of Learning Methods (편향)
: 예측값들과 정답이 대체로 멀리 떨어져 있으면 결과의 편향(bias)이 높다고 한다.
: 편향은 실제 문제 (일반적으로 매우 복잡함)를 훨씬 단순한 문제로 모델링하여 발생하는 오류를 나타냅니다.
: 선형 회귀는 Y와 X 사이에 선형 관계가 있다고 가정합니다.
: 방법이 더 유연하고 복잡할수록 일반적으로 편향이 적습니다.
- Variance and Bias Image (비교)

- K-NN 장단점 비교
장점.
: 단순하고 이해하기 쉽다.
: 명시적인 거부 표현 (k 값에 대한 과반수 동의가없는 경우)
: 결측 값의 손쉬운 처리가 가능하다.
: 최적의 값에 가깝다. (점근적 오 분류 율은 Bayes 오류율의 두 배 이상으로 제한됩니다.)
단점.
: Big O 값이 크다. (n : sample, m : feature)
: 대용량 메모리를 요구로 한다.
: 더 빈번한 훈련이 결과를 지배한다.
: 노이즈에 민감하고, feature에 무관하다.
: 차원이 높을수록 계산이 많아진다. ("가장 가까운" 이웃은 매우 멀리있을 수 있다. 높은 차원에서 "가장 가까운"은 의미가 없다.)
- Choice of Distance Measure (거리 측정 선택법)
- Euclidean distance
· 각각 스케일이나 분포가 비슷해야함 (표준화, 정규화)
- Manhattan distance (x, y축 수직으로의 이동 거리)
- Lp norm
- Mahalanobis distance (Covarience Matrix)
- 1-Correlation
- 1-Cosine similarity
· Consider only the direction between the two vectors (not the magnitude)
· Compute using dt product (inner product)
- Curse of dimensionality (차원의 저주)
- 데이터 공간의 크기는 차원 수에 따라 기하 급수적으로 증가합니다.
- 동일한 밀도를 유지하려면 데이터 세트의 크기도 기하 급수적으로 증가해야 합니다.
- KNN 알고리즘에서는 모든 축에서 두 점이 매우 가까워야합니다.
· 새로운 차원을 추가하면 포인트가 더 멀어 질 수있는 또 다른 기회가 생성됩니다.
- KNN에서 극복하는 방법
· Add more data...
· Reduce dimension (feature selection, feature extraction)
아주대학교 정보통신대학원 손경아 교수님의 기계학습 및 데이터 마이닝 강의를 바탕으로 작성하였습니다.
학습 목적으로 포스팅 합니다.
'Machine Learning' 카테고리의 다른 글
| Decision Tree (0) | 2020.09.12 |
|---|---|
| Support Vertor Machine (0) | 2020.09.12 |
| 탐색적 데이터 분석 (Exploratory Data Analysis) (0) | 2020.09.05 |
| 데이터 및 데이터 품질 (0) | 2020.09.05 |
| 기계학습과 데이터마이닝 (0) | 2020.09.05 |