- 데이터
데이터는 Instances 및 해당 Instances의 Attributes에 대한 모음이라고 표현할 수 있습니다.
Attributes는 인스턴스의 속성 또는 특성으로 Instances와 Attributes는 아래와 같이 다른 이름으로 표현 가능합니다.

=> Attributes: 인스턴스의 특성 측정 (variable/feature/characteristics/field)
=> Instances: 개념의 개별적이고 독립적 인 예 (sample/record/point/case/object)
- Type of Variables
데이터 변수의 타입은 아래와 같이 Categorical 형과 Numeric 형으로 분류할 수 있습니다.
Categorical 형의 하위에는 Nominal, Ordinal이, Numeric 형의 하위에는 Discrete,Continuous 가 있습니다.
- Categorical (범주형)
· Nominal (명목형): No relation is implied among nominal values
· Ordinal (순위형): Impose order on values
- Numeric (수치형)
· Discrete (이산형): Has only a finite or countably infinite set of values
· Continuous (연속형): Has real number as attribute value

=> 대부분의 기계학습 데이터마이닝 알고리즘은 Input, Feature Type이 Specific form(특정한 형태)임을
가정하기 때문에 Type이 중요합니다.
- One-hot encoding
One-hot encoding 이란, 단 하나의 값만 True의 값을 가지고 나머지 값은 모두 False의 값을 가지는 인코딩을 말합니다.
단어 집합의 크기를 벡터의 차원으로 하여 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0의 값을 부여합니다.
즉, 1개만 Hot(True)이고 나머지는 Cold(False) 입니다.
- Categorical (범주)형 데이터에 대한 표준 접근 방식
- 각 범주 형 값을 나타내는 이진 벡터 만들기
- 범주 형 데이터의 표현을 보다 효과적으로 표현 가능

=> 다섯가지 색의 Categorical (범주)형 데이터에 대해 One-hot encoding을 진행하였습니다.
- One-hot encoding 시 주의사항
· 문제점: blue: 0, green:1, red:2
· 표현법: One-hot encoding을 사용하여 binary vector로 표현
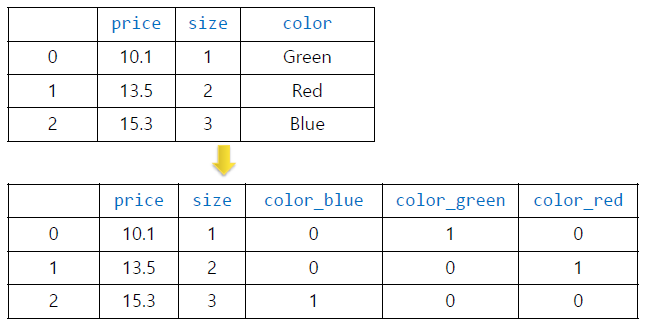
=> 알고리즘이 이 값을 수치형으로 간주하여 기대하지 않은 (최적이 아닌) 결과를 초래할 수 있습니다.
=> blue: 100, green: 010, red: 001 로 표현합니다.
- Text 데이터 표현법
1. Traditional TF-IDF (Term Frequency - Inverse Document Frequency)
TF-IDF는 정보 검색과 텍스트 마이닝에서 이용하는 가중치로, 여러 문서로 이루어진 문서군이 있을 때
어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치입니다.
문서의 핵심어를 추출, 검색 엔진에서 검색 결과의 순위를 결정, 문서들 사이의 비슷한 정도를 구하는 등의 용도로 사용할 수 있습니다.
2. Word embedding technoques: Word2vec, Glove, fastText, BERT
자연어 처리에서 Word embedding은 텍스트 분석을 위해 단어를 표현하는 데 사용되는 용어로, 일반적으로 벡터 공간에서 더 가까운 단어가
예상되도록 단어의 의미를 인코딩하는 실수 벡터 형식입니다. 대표적으로 Word2vec, Glove, fastText, BERT가 존재합니다.
3. Pre-trained models
사전학습을 끝낸 이후에 산출물로 나온 모델을 말합니다.
사전학습 된 모델이란, 내가 풀고자 하는 문제와 비슷하면서 사이즈가 큰 데이터로 이미 학습이 되어 있는 모델입니다.
그런 큰 데이터로 모델을 학습시키는 것은 오랜 시간과 연산량이 필요하므로, 주로 이미 공개되어있는 모델들을 import해서 사용합니다.
- Image 데이터
Image 데이터는 매우 높은 차원의 데이터를 가집니다. (e.g. (w x h x 3)-dim)
전통적으로는 PCA 기법 등을 사용하여 차원 축소를 하였으나, 최근에는 CNN 같은 딥러닝 모델을 사용합니다.
- Traditionally: PCA (주성분분석, Principal Component Analysis) 등 차원 축소 기법
- Recently: deep learning models such as convolutional neural networks (CNN (Convolutional Neural Network))
- Ordered 데이터
Ordered 데이터는 독립적이지 않고 이전 순서의 데이터가 다음 과정에 영향을 미치는 데이터입니다.
- Time-series / sequential data
- Genomic sequence data
- Models such as Hidden Markov Model, Recurrent Neural Networks
- Graph 데이터
Grapg 데이터는 행렬 혹은 리스트로 표현이 가능합니다.
하지만 행렬로 표현할 경우, 0으로 비어있는 부분 (Sparse data)이 많이 생길 수 있으니 주의가 필요합니다.
- ex) soical network, biological network, HTML Links

- Sparse 데이터
Sparse 데이터는 차원/전체 공간에 비해 데이터가 있는 공간이 매우 협소한 데이터를 의미합니다.
반대로, Dense 데이터는 차원/전체 공간에 비해 데이터가 있는 공간이 빽빽하게 차 있는 데이터를 의미합니다.
- 어플리케이션에서 데이터 세트의 대부분의 속성 값은 0
- ex) 자연어 처리의 문서 벡터 (햐얀 곳이 0의 값으로 Sparse 데이터가 많다.)

- 데이터 품질 문제
데이터의 품질 문제는 Missing values (결측 데이터), Noise and outliers (노이즈 및 이상값), Nomalization (정규화) 문제로 발생합니다.
1. Missing values (결측 데이터)
: 결측 데이터 발생 및 처리
- Reasons for missing values
· 수집 과정의 에러
· 수집되지 않은 정보
· 특정 측정 기준은 적용 불가능
- 데이터 테이블에서 주로 빈 공간이나 NaN (not a number)로 표시
- 결측 데이터를 무시하는 경우 예측할 수 없는 결과를 낳게 됨
· 예: 0으로 표시 (x)
: 결측 데이터 탐지 방법
- Handling missing values
· 결측행이나 열 제거시 => 정보 부족 문제발생

: 결측값 보정 (imputation)
- 평균보정법: 열 (column) 평균 사용
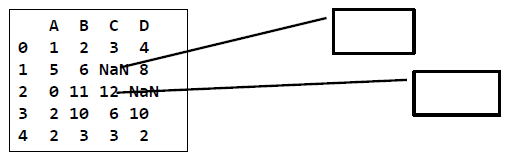
- K-Nearest Neighbor Imputation: 자신과 가장 비슷한 것을 참고

2. Noise and outliers (노이즈 및 이상값)
: 이상값 원인 및 처리
- Measurement error
- Human error
- Samling error
- Natural outlier
: 이상값 처리
- 변수화: 특정 여부에 따라 0-1로 변수화
- 리샘플링: 이상치를 삭제하고 분석 범위를 조절하여 새로운 모델 구성
3. Feature scaling
Feature scaling 이란 데이터 전처리 과정의 하나입니다.
데이터의 값이 너무 크거나 혹은 작은 경우에 모델 알고리즘 학습과정에서 0으로 수렴하거나 무한으로 발산해버릴 수 있기 때문입니다.
이 과정을 통해 머신러닝 알고리즘들은 피처들이 동일한 스케일에 있는 경우 더욱 잘 동작하도록 설정해줄 수 있습니다.
: Normalization (정규화)
정규화는 데이터의 범위를 0과 1로 변환하여 데이터 분포를 조정하는 방법입니다.
(해당값-최소값) / (최대값-최소값) 을 해주면 됩니다.

: Standardization (표준화)
각 observation이 평균을 기준으로 어느 정도 떨어져 있는지를 나타낼때 사용됩니다.
값의 스케일이 다른 두 개의 변수가 있을 때, 이 변수들의 스케일 차이를 제거해 주는 효과가 있습니다.
제로 평균 으로부터 각 값들의 분산을 나타낸다. 각 요소의 값에서 평균을 뺀 다음 표준편차로 나누어 줍니다.
· Mean

· Variance

· Standard deviation

아주대학교 정보통신대학원 손경아 교수님의 기계학습 및 데이터 마이닝 강의를 바탕으로 작성하였습니다.
학습 목적으로 포스팅 합니다.
'Machine Learning' 카테고리의 다른 글
| Decision Tree (0) | 2020.09.12 |
|---|---|
| Support Vertor Machine (0) | 2020.09.12 |
| KNN algorithm (0) | 2020.09.12 |
| 탐색적 데이터 분석 (Exploratory Data Analysis) (0) | 2020.09.05 |
| 기계학습과 데이터마이닝 (0) | 2020.09.05 |